
Understanding a complex codebase is hard, not just for humans but for AI too. Bito’s AI Code Review Agent is built to handle that challenge. It uses a mix of techniques to actually understand your code, and provide codebase aware AI code reviews.
Bito’s working architecture breaks the code into smaller pieces, indexes and embeds them so they’re easy to look up later. Then it runs AI models to generate feedback that feels like it came from a real engineer.
All of this happens with your code’s security and privacy in mind.
In this breakdown, I’ll walk you through how the agent works under the hood. We’ll cover how it reads and understands your code, how it writes and improves its reviews based on your team’s feedback, and how it keeps everything secure. Let’s get into it.
Core architecture and components of Bito
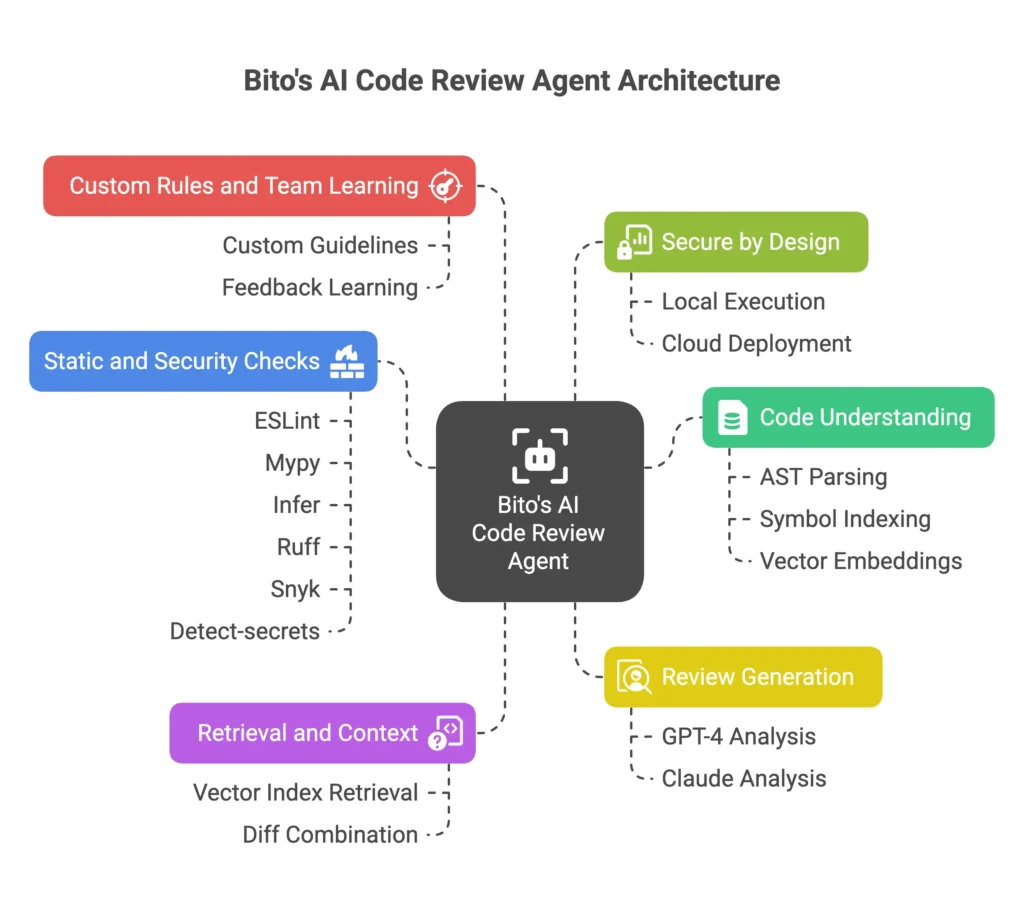
Bito’s AI Code Review Agent is made up of several tightly connected systems. Together, they help the agent understand your codebase, run intelligent reviews, and learn from your feedback. Here’s how it works under the hood:
1. Code understanding
Before each review, Bito parses your code into ASTs, builds a symbol index, and generates vector embeddings for files, functions, and comments. This gives the agent a rich, structured view of your repo and helps it reason across files.
2. Retrieval and context
All embeddings are stored locally. When a review runs, Bito retrieves relevant code from your vector index and combines it with the current diff. This gives the model visibility into surrounding logic, not just the lines that changed.
3. Review generation using LLMs
The agent uses models like GPT-4 or Claude to analyze the diff in context. It comments inline, flags bugs, suggests fixes, and reasons about logic, performance, and security issues like a senior dev.
4. Static and security checks
Bito integrates tools like ESLint, Mypy, Infer, Ruff, Snyk, and detect-secrets. These add an extra layer of checks, covering both style and real security risks.
5. Custom rules and team learning
You can define your own guidelines in the dashboard. Bito also learns from your feedback and auto-generates rules when you repeatedly reject similar suggestions. This helps the agent align with your standards over time.
6. Secure by design
All indexing and review logic run locally or in your cloud. Nothing is sent for training. You can deploy on-prem, route inference through AWS or Azure, and meet enterprise security standards.
With these components, Bito’s Code Review Agent essentially builds a “code brain” that knows your codebase inside-out and can discuss it intelligently. Now, let’s see how it parses and understands your code step by step.
Parsing and understanding code with Indexing, ASTs, and Embeddings
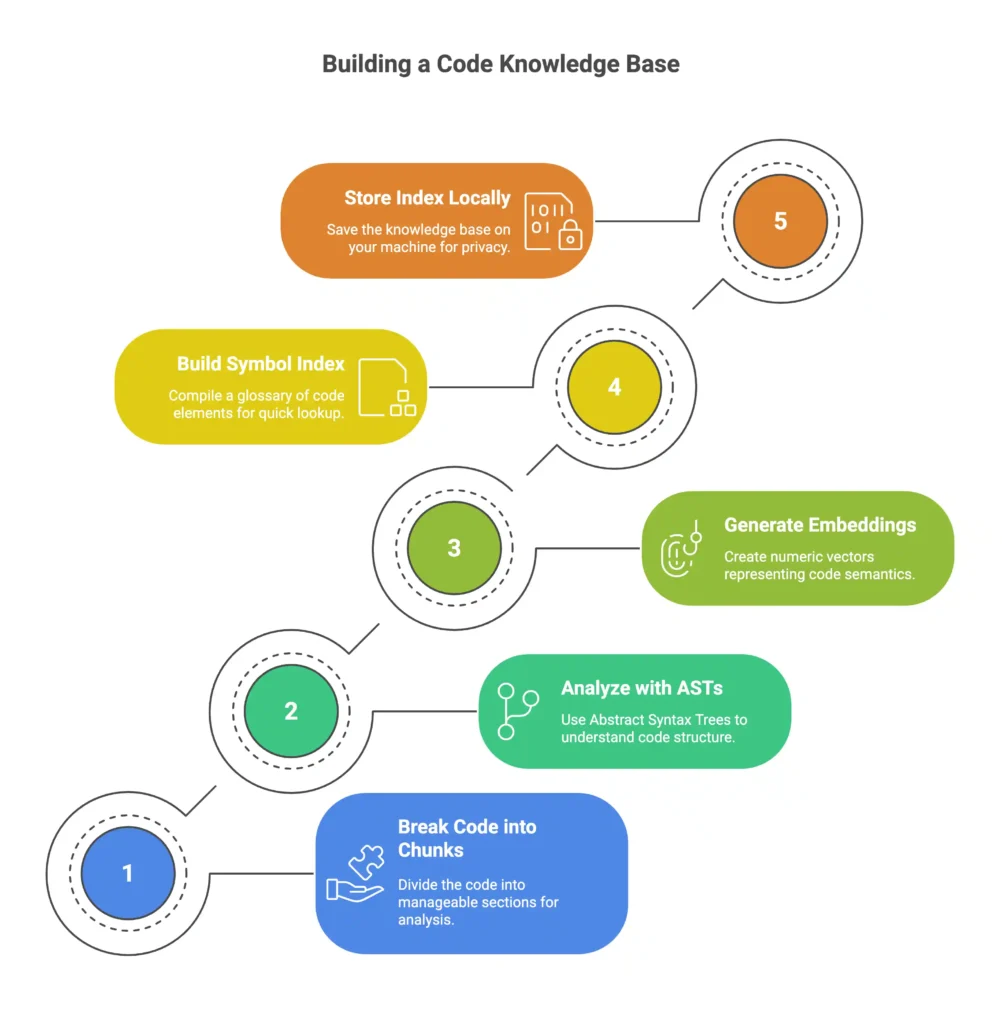
Before Bito can review code, it first needs to understand it. That starts with indexing. Bito breaks the code into smaller parts, analyzes the structure with ASTs, and generates embeddings for semantic understanding.
1. Breaking code into chunks
Bito begins by slicing your source files into smaller sections or chunks for manageability. Think of this like splitting a long article into paragraphs.
Each chunk is a self-contained piece of code, such as a function or a logical block, that can be indexed and analyzed independently.
After splitting, each chunk gets an index entry so it can be referenced later. This index acts like a catalog that maps code locations to their content.
2. Analyzing structure with ASTs
At the same time, Bito parses your code into Abstract Syntax Trees. An AST is a tree representation of the code’s syntax. It shows how the code is organized into constructs like classes, functions, loops, and conditionals.
By examining the AST, Bito understands relationships such as which class a function belongs to, what parameters it has, and what it calls internally.
For example, if you have a function called authenticateUser, the AST helps Bito see the context around that function. It understands whether it is defined inside a UserAuth class, whether it calls other functions, or whether it appears inside a conditional.
This structural understanding is important for assessing the scope and impact of changes.
3. Generating embeddings for code semantics
For every chunk of code, Bito creates an embedding. An embedding is a numeric vector that represents the meaning of a code snippet. Embeddings are like fingerprints. Code that does similar things will have embeddings that are mathematically close together.
Bito uses a model, such as OpenAI’s text-embedding-ada-002, to convert code into this vector form. So if two different functions both implement an add operation, their vectors will be near each other.
Unrelated code will be further apart in this vector space. These embeddings help the agent capture semantic relationships that go beyond keyword matching.
At this point, Bito has created a numerical map of your codebase.
4. Building the symbol index
In parallel with embeddings, Bito builds a symbol index. This includes all function names, class names, variables, and where they appear in the code. This symbol index acts like a glossary of your codebase.
It allows fast lookup of definitions and references. For example, if a function called authenticateUser was modified, the agent can quickly find every place that function is called.
Bito’s symbol search engine is optimized to find relevant references in just a few milliseconds.
5. Storing the index locally
All the chunk indices, embeddings, and symbol references are stored in a local database. This is usually a file on your machine, often located under ~/.bito/localcodesearch.
This vector database contains entries like file name, line numbers, vector values, and the function or block contained in that chunk. Because the database is stored locally, none of your code leaves your environment during this process.
By combining ASTs, embeddings, and symbol indexing, Bito builds a code knowledge base.
This gives the agent multiple ways to understand and reason about your codebase.
That foundation is what enables accurate and context-aware code reviews.
Vector index and Retrieval-Augmented Context
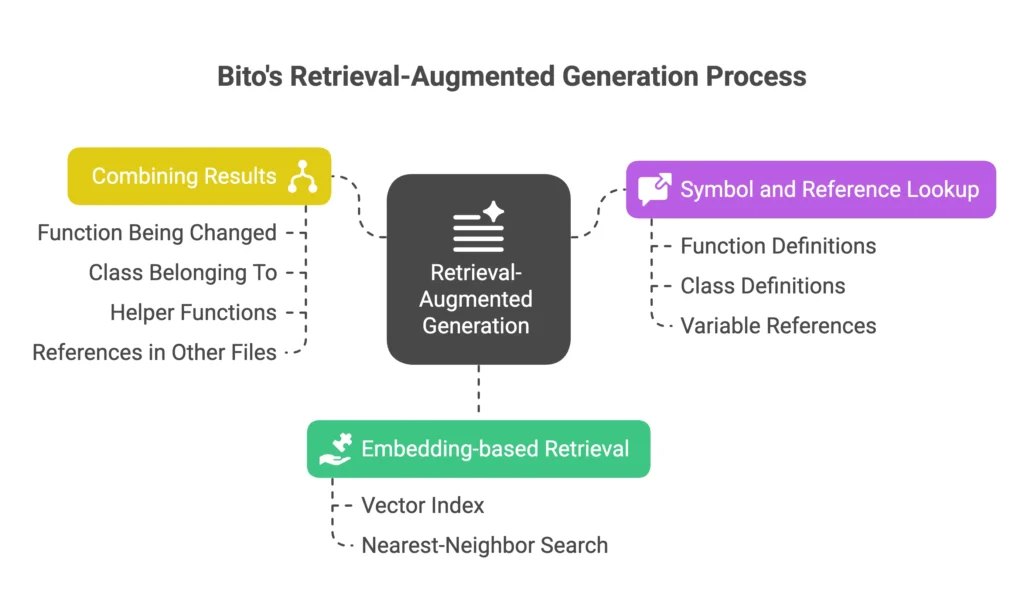
One of the standout features of Bito’s approach is using Retrieval Augmented Generation (RAG), which is a fancy way of saying “the AI grabs relevant knowledge before answering.”
In practice, this means when the code review agent is analyzing a pull request or answering a question, it doesn’t rely on the LLM’s memory alone, it actively retrieves context from your codebase.
Embedding-based retrieval using vector index
When a review or question comes in, Bito first converts the input into an embedding. This embedding is a vector that captures the meaning of the request.
Bito then searches a local vector database, located at .bito/localcodesearch, to find the most relevant code snippets from your codebase. This is a nearest-neighbor search.
If you ask where a certain logic is implemented, or the agent needs to understand a specific change, it retrieves the closest matches based on meaning.
Symbol and reference lookup
In parallel, Bito uses a symbol index. This index tracks where functions, classes, and variables are defined and referenced across files. If a pull request modifies a method like authenticateUser, the symbol index helps the agent pull in the definition and all other files that use it. This allows the agent to see how the change connects with the rest of the repo.
Combining the results
Once both the vector search and symbol lookup are done, Bito combines the results into a single context bundle. This can include the function being changed, the class it belongs to, any helper functions it calls, and references in other files.
The agent uses this combined context as the basis for generating review comments or answers.
This is a core reason the agent is able to review like someone who has read and understood your repo.
Generating the review: LLMs and multi-faceted analysis
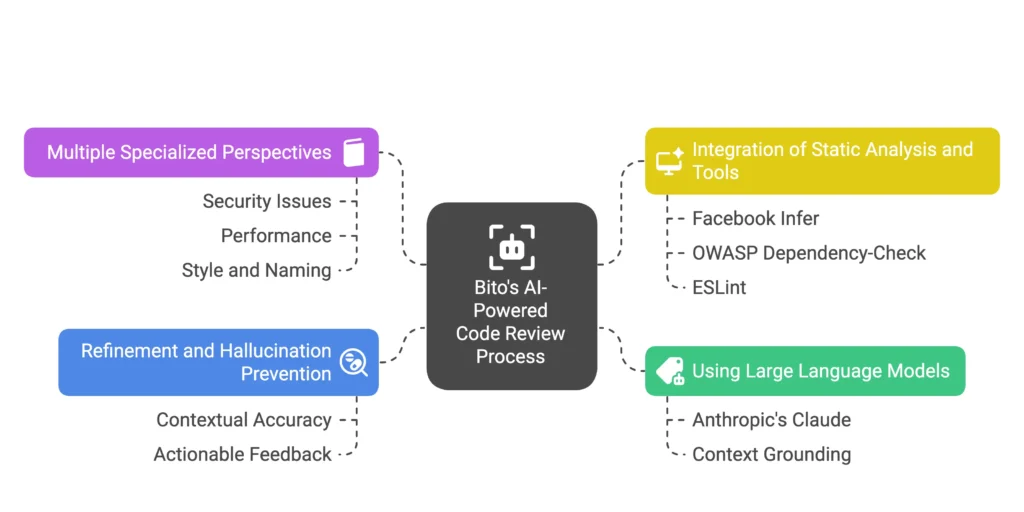
Once the relevant context is gathered, the next step is for the AI to generate the code review comments. Bito uses generative AI models to do the heavy lifting, but with a structured method to make sure the output is useful.
1. Using large language models
Bito’s agent feeds the collected context into a language model prompt. This includes the code diff, related code retrieved through embedding search, and any other context. The model used heavily is Anthropic’s Claude, selected based on complexity and speed.
Because the context is grounded in your actual repository, the model is able to make relevant observations. It can reason about how the changed code interacts with other parts of the system, not just what changed.
The comments it generates are phrased like a human reviewer. They are specific, conversational, and often include reasoning or suggestions.
2. Multiple specialized perspectives
Bito does not treat the AI as one general-purpose reviewer. Internally, it breaks down the review into categories. Think of this like having different specialists look at the code.
There is a pass for security issues.
Another for performance.
Another for style and naming.
Each one contributes a set of comments. This way, the feedback is detailed and labelled clearly. You will often see themes like security, optimization, or formatting in the comments.
3. Integration of static analysis and tools
Bito does not rely only on the language model. It also runs static analysis tools and adds their output to the review.
For example, it uses Facebook Infer to detect null dereferences, resource leaks, or type errors. It also integrates security tools like OWASP Dependency-Check, Snyk, or detect-secrets. If a new dependency has a critical CVE, the agent flags it. It may even suggest a fix, like upgrading to a safe version.
Linters are also part of this setup. The agent uses tools like ESLint, Ruff, and Mypy for formatting and typing checks. The results are merged with the LLM-generated comments into a single review output.
This means you get a comprehensive review. The agent covers both AI-identified issues and issues found through static tools. If the function is missing a type annotation, it points it out and suggests the right fix. If a secret is committed by mistake, the scanner catches it.
4. Refinement and hallucination prevention
Bito is designed to avoid AI hallucinations. Because the model only sees retrieved code from your repository, the risk of made-up feedback is lower. If a comment does not align with the facts, the system can remove or revise it before posting.
The final output is a set of review comments, each grounded in real context. They are specific, actionable, and safe to rely on. You can view them in the pull request or directly in your IDE.
Custom rules and learning from team feedback
This is a really cool feature we’re bullish on.
Bito adapts to how your team works. It does not enforce generic rules. Instead, it learns from your reviews and lets you define your own standards.
Enforcing custom guidelines
Teams can provide Bito with their own review rules. Bito gives you a way to configure rules directly. You can change thresholds or disable certain checks.
For example, you might want to ignore method length unless it exceeds 30 lines. You can codify these rules and make the AI reviewer behave like your team would.
The goal is for the agent to feel like part of your team. It starts with general knowledge but gets better with every review. After a few weeks of feedback and tweaks, it begins to speak your team’s language.
Learning from pull request feedback
When the agent posts comments, you can give feedback on them. If certain suggestions are always marked as not useful, Bito learns. After seeing the same pattern rejected multiple times, it creates new rules under the hood. These rules help it avoid repeating the same suggestions in future reviews.
Over time, this makes the review output better aligned with your team’s style. It avoids nagging on things you do not care about and focuses on what matters.
Security and privacy by design
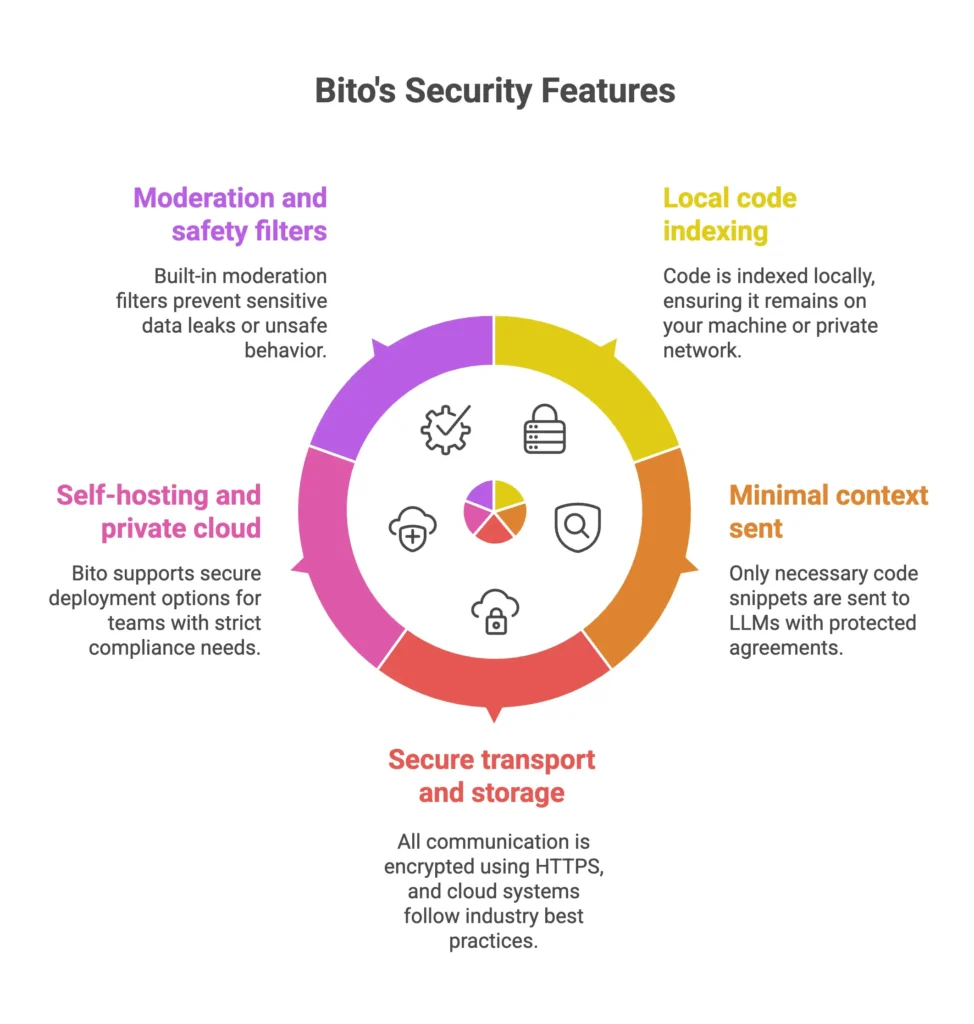
When using any AI tool that interacts with proprietary code, security and privacy are non-negotiable. Bito’s architecture takes a security-first approach to ensure that your code remains under your control.
Local code indexing
Bito indexes your codebase locally. The process of breaking your code into chunks and generating embeddings happens entirely on your machine or within your private network.
The resulting vector index is stored on your local system, not in Bito’s cloud. When the AI Code Review Agent runs, whether in a CI pipeline or inside your IDE, it uses this local index to retrieve relevant code snippets. Your full codebase never leaves your infrastructure.
Minimal context sent to LLMs with protected agreements
To generate a review or answer a question, the AI model may need to see part of your code. Bito only sends what is absolutely necessary. Just the small, relevant snippets needed for the task. It does not send your entire repository or unrelated code.
The language model providers Bito uses, like OpenAI or Anthropic, operate under strict agreements. They do not store your code or use it for training. Inputs are processed and immediately discarded.
Secure transport and storage
All communication between the Bito agent, its cloud services, and the LLM APIs is encrypted using HTTPS. This ensures end-to-end encryption for all data in transit.
Bito’s cloud systems follow industry best practices. The company is SOC 2 Type II certified, which means it has passed an independent audit of its internal security controls. This includes access control, monitoring, and encryption at rest.
Optional self-hosting and private cloud deployment
For teams with strict compliance needs, Bito supports multiple secure deployment options. You can install and run the Code Review Agent on premises or inside your own virtual private cloud.
Bito also integrates with cloud-native services like AWS Bedrock and Azure AI. This allows inference to happen inside your secure cloud environment rather than on a public endpoint.
Moderation and safety filters
Bito includes built-in moderation across all AI interactions. Prompts and responses are automatically filtered to prevent sensitive data leaks or unsafe behavior.
If a user accidentally or intentionally tries to generate inappropriate output or expose secrets, Bito’s safety system flags and blocks it. This ensures the AI assistant stays safe, reliable, and usable in enterprise environments.
Conclusion
Everything Bito does before a review is what makes the review worth reading. It splits your code into chunks. Parses them with ASTs, embeds, indexes, and stores everything locally.
So when it generates a comment, it’s not guessing. It’s pulling real context. That’s the difference. You’re not just getting a “smart” comment. You’re getting a comment from an agent that actually understands your codebase.
If you want your AI code reviews to feel like they came from someone who’s read your repo before, try Bito.
Runs locally. Respects your setup. Takes two minutes to start.
FAQs
Q1. What does “codebase-aware” mean for an AI code review tool?
It means the tool does not just look at the diff. Bito parses your code into ASTs, builds a symbol index, and stores embeddings so it can fetch related files, callers, and dependencies before it comments on a change.
Q2. How does Bito build and maintain its understanding of a codebase?
It splits files into chunks, analyzes structure with ASTs, and creates embeddings for functions, classes, and comments. Those embeddings sit in an index that can be queried whenever a new review runs.
Q3. Does Bito need to re-scan the whole repo for every AI code review?
No. Once the index is built, Bito only pulls the parts of the codebase that are relevant to the diff. That keeps reviews fast while still giving the model the context it needs.
Q4. How does Bito combine static analysis and AI?
Bito runs static and security tools like ESLint, Mypy, Infer, Ruff, Snyk, and detect-secrets alongside LLMs. Static checks catch rule-based issues, while the AI looks at logic, structure, and intent.
Q5. Does this codebase-aware setup affect code privacy?
No. Indexing and retrieval run in your environment, and nothing from that index is used for model training. The index is only there to provide better context while keeping your code under your control.





