
When a change spans five services, three repos, and multiple data flows, code review becomes fragile. Small schema updates can break things in ways no one notices until later.
To demonstrate this, we’ve built a sample system with five microservices and a shared UserProfile interface.
- User Service manages user profiles
- Events Service emits updates to an analytics pipeline
- API Gateway exposes user data
- Analytics and Notification Services react to user activity
Now, we add a new field, avatar_url, to the shared UserProfile interface:
// common-proto/user.ts
export interface UserProfile {
id: string
name: string
email: string
avatar_url: string // new field
}
That should be simple. But one service forgets to map the field. Another left it out of the event payload. The API Gateway passes along incomplete data without noticing. Lastly, Analytics and Notification services miss the new value.
This post walks through the actual code change and pull request that causes that bug to slip through. First without Bito. Then with it.
What breaks when code reviews miss multi-service context
We add avatar_url to the shared UserProfile schema. Every service using this interface is expected to pick it up. That does not happen though. Here’s where it breaks:
1/ user service: omits the field in response
- The model includes avatar_url, but the profile handler skips it in the response.
- The field is missing in the actual API output, even though the schema defines it.
- No linting or type checks fail.
2/ events service: skips the field in emitted events
- The event producer constructs the payload but forgets to include avatar_url.
- The event publishes successfully. No schema validation flags it.
- Downstream consumers get a payload that looks valid but lacks the new field.
3/ api gateway: passes through incomplete data
- The gateway proxies the profile from user service to the client.
- Since the user service response is missing avatar_url, the gateway also returns a partial object.
- There’s no logic in place to check for field presence.
4/ analytics and notification services: receive and process stale data
- These services subscribe to the UserUpdatedEvent.
- They store the data and trigger logic based on it.
- They never see the new field and keep working with incomplete state.
As you can see, everything looks fine on the surface. The profile schema updates in one place, and the rest of the system keeps running. But the gaps only show up later.
A missing field means incomplete data. That data flows into services downstream, and the issue spreads without anyone noticing. These are the kinds of bugs that make it all the way to production before someone finally traces them back to a line in a pull request.
What you’d catch (or miss) in a manual review
Suppose you’re a senior developer who’s managing a team, writing code, building infra, and reviewing this pull request. You’ve got limited time and context.
The PR adds avatar_url to the shared UserProfile schema, and at first glance, things look clean. Tests are green, CI passed, and the description says the new field was added.
You check profile.ts in the user service. The handler constructs the profile response like this:
const profile: UserProfile = {
id: user.id,
name: user.name,
// avatar_url is missing here
}
The handler skips mapping avatarUrl. There’s no type error because UserProfile expects avatar_url, and the compiler can’t enforce that runtime object shape.
The only way to spot this is to mentally diff the shared type with every place it gets constructed or consumed.
That means jumping into at least four other services, checking if the field flows end to end, and making sure consumers downstream receive and use it. Doing that across repos and services takes serious attention, and most reviewers don’t have time to dig this deep into every PR.
Bugs like this don’t show up in CI. They slip through code review and show up weeks later in user reports or missing metrics.
How Bito handles the same PR with full context
Now let’s see how Bito’s AI Code Review Agent reviews the same pull request. This one spans 596 lines across 23 files. It affects five services and includes changes to shared types.
Normally, just as we discussed: a reviewer would jump between files, trace changes across services, and try to catch inconsistencies by hand. Bito does all of this in minutes.
As soon as the pull request opens, Bito analyzes the codebase and builds a system-level view. It connects schema updates, service logic, event flows, and data consumers. Then it flags real issues tied to functionality, not formatting.
What Bito flagged
1. Incomplete event payload
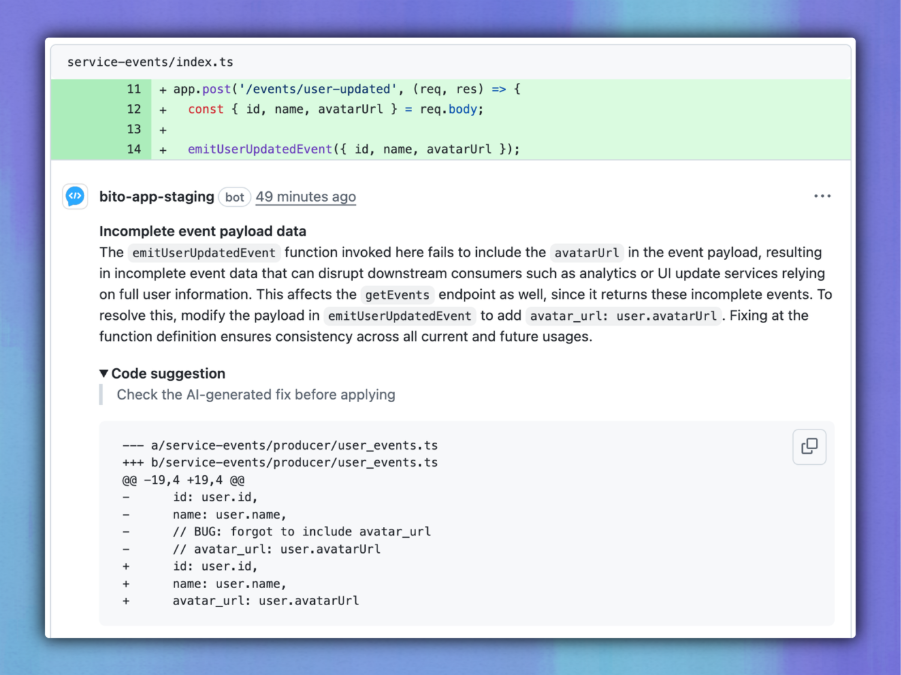
File: service-events/index.ts
The code calls emitUserUpdatedEvent but leaves out avatar_url. Bito detects that the payload lacks the new field and highlights how it affects downstream consumers. It also recommends fixing it inside the emitter function to keep things consistent across future uses.
2. Unsafe event casting without validation
File: service-analytics/consumer/event_processor.ts
The code casts an incoming event to UserUpdatedEvent without checking that required fields exist. If the payload is malformed or incomplete, this can break analytics data silently. Bito flags this and suggests adding validation before casting.
3. Missing error handling in event endpoint
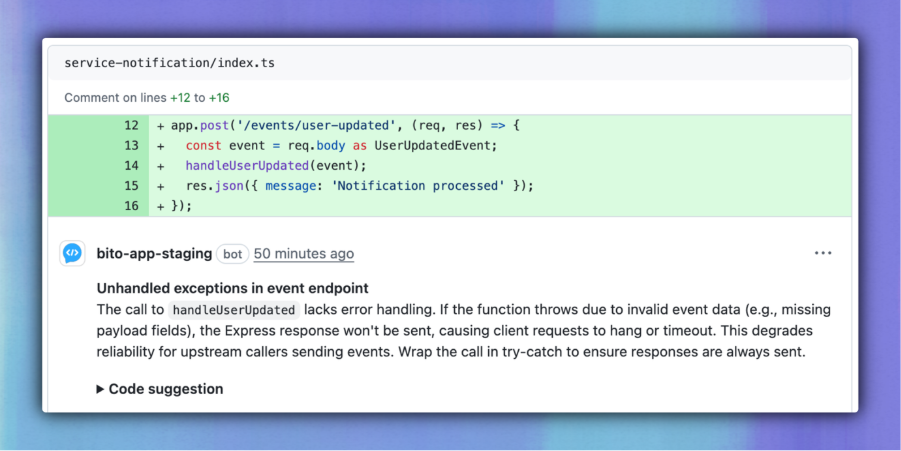
File: service-notification/index.ts
The notification service processes incoming events without catching exceptions. If a bad event arrives, the function throws and leaves the request hanging. Bito identifies this and recommends a try-catch to handle failures gracefully.
Each suggestion includes exact line references, an explanation of why it matters, and a fix. All of this shows up directly in the GitHub pull request.
Bito used across teams, at scale!
In the last month, Bito reviewed more than 20,000 pull requests across 1,750 repositories. It flagged over 24,000 issues, most related to logic, test coverage, or broken flows across services.
It plugs into the review loop without changing how teams work. No new dashboard, no switching tools. It works natively inside GitHub, GitLab, Bitbucket, and popular IDEs.
What makes it work across large systems:
- Codebase-aware reviews: Bito maps service boundaries, shared modules, and schema flows so it can catch issues that ripple across repos.
- Custom review rules: Teams define rules through feedback, dashboard settings, or project guideline files. Bito learns and enforces them automatically.
- Jira and ticket context: Bito reads linked tickets, matches code to expected behavior, and flags any drift from the intended change.
- Fast, consistent feedback: Reviews run as soon as the pull request opens. Teams get system-level suggestions before someone picks up the review.
This is how engineering orgs keep review quality high without adding more meetings or slowing down deploys.
“Before Bito, some PRs stayed open for over a week. Now, submitters fix most issues before I even see the code, and reviews often take just 10 to 20 minutes instead of an hour.”
Parting words
Multi-service reviews demand more than syntax checks or pass-fail CI. Reviewers need system-level awareness like what changed, where it flows, and what it impacts downstream. That context rarely lives in one file or even one repo.
Bito gives that context upfront. It connects type updates to service behavior, flags logic gaps before they merge, and scales feedback across codebases without adding review burden. It runs inside GitHub and IDEs, respects your custom rules, and catches the stuff that slips past checklists.
If your team works across services and ships often, run Bito on your next pull request and see what it finds before you even open the diff.
FAQs
Q1. Why are multi-service pull requests so hard to review manually?
They touch several services or repos at once, and a reviewer has to reconstruct how APIs, events, or shared libraries interact. That takes time and makes it easy to miss a cross-service break.
Q2. How can an AI code review tool help with multi-service PRs?
A codebase-aware AI code review tool can pull context from the other services, check callers and callees, and flag cases where a change in one service silently breaks another.
Q3. Does AI code review still work if services live in separate repositories?
Yes, as long as the agent can index the relevant repos or monorepos. Once indexed, it can follow calls and data flows across services even when they sit in different projects.
Q4. How do AI comments differ from normal review comments on a multi-service PR?
The AI can reference related files in other services, explain impact on upstream or downstream calls, and link suggestions to specific flows instead of just pointing at a single line in isolation.
Q5. Will using AI code reviews slow down multi-service releases?
No. The point is to front-load more context and issues into the first pass so you spend less time going back and forth later, especially when multiple teams are involved in the same PR.





