
If you have searched for the best AI code review tool recently, you have probably seen a lot of claims. But as a developer, you know what matters is how it actually performs when run on real code.
That is what this benchmark report is about.
We built a Truth Set of 65 known issues across different severities and ran Bito against it, along with a few other tools. Each agent was scored based on how many real problems it could catch.
The results you see here are based on that snapshot. We keep updating the benchmark as the agents improve. You can always find the latest numbers here in our benchmarks page.
This blog walks through what we tested, how we measured it, how Bito performed, and how this could help your team decide what to try next.
How we measured Bito’s AI code review tool performance

When it comes to finding the best AI code review tool, performance in actual code matters more than feature lists or UI walkthroughs. This benchmarking of AI code reviews focused on how well each tool reviews real pull requests and how useful its feedback actually is.
Benchmarking criteria of the best AI code review tool: coverage and precision
We looked at two things.
- Coverage: This measures how many of the known issues in the code were flagged by the tool. Higher coverage means the tool picks up more of what would normally get caught in a team review.
- Precision: This tracks how many of those suggestions were accurate and worth applying. It helps separate helpful insights from noisy or incorrect advice.
Language support
Languages included in the benchmark:
- TypeScript
- Python
- JavaScript
- Go
- Java
Each test was built on real examples with real issues. These were bugs, patterns, and mistakes that show up all the time in active codebases.
Every tool was run on the same benchmark. Same codebase. Same issue set. This keeps the results clean and makes it easier to compare what each tool can actually do.
Bito’s AI code review benchmark results
We designed the AI code review benchmarking to evaluate how effectively Bito’s AI Code Review Agent detects real issues in actual codebases.
Each file in the truth set contained known problems, helping benchmark how well each AI code analysis tool handles real-world software issues. These included logic bugs, structural issues, performance bottlenecks, documentation gaps, and concerns affecting code maintainability.
Overall issue detection rate
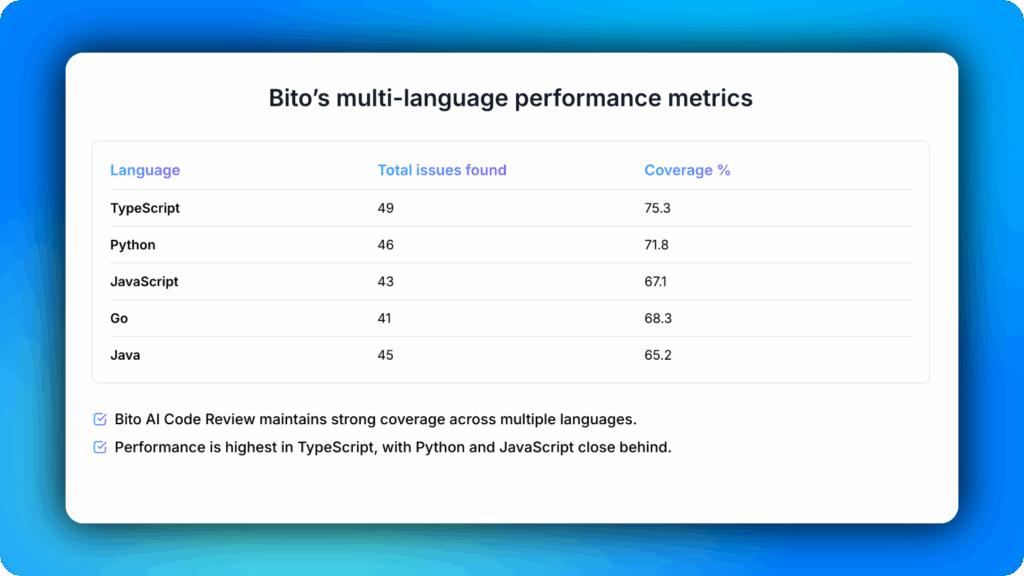
As I’ve already mentioned, Bito was tested across five programming languages: TypeScript, Python, JavaScript, Go, and Java.
The agent reviewed each file without any prompt tuning or additional configuration. We measured its performance based on the proportion of known issues it correctly identified and the accuracy of its suggestions.
The average coverage across all five languages was 69.5 percent.
This indicates Bito’s consistent ability to detect a significant portion of real-world issues across diverse codebases.
Comparison with other tools
To contextualize Bito’s performance, we ran the same benchmark on several other tools. Coderabbit achieved an average coverage of 65.8 percent, coming closest to Bito.
Other tools like Entelligence, Graphite, Gemini, Copilot, Qodo, and Codeant showed lower coverage rates and exhibited more variability across different languages.

Detection by issue type
Beyond overall coverage, we analyzed the types of issues Bito detected. Logic and structural issues came off as the most detected issues types compared to other categories.
These types of problems are often more challenging to catch and can lead to significant bugs if overlooked during code reviews.

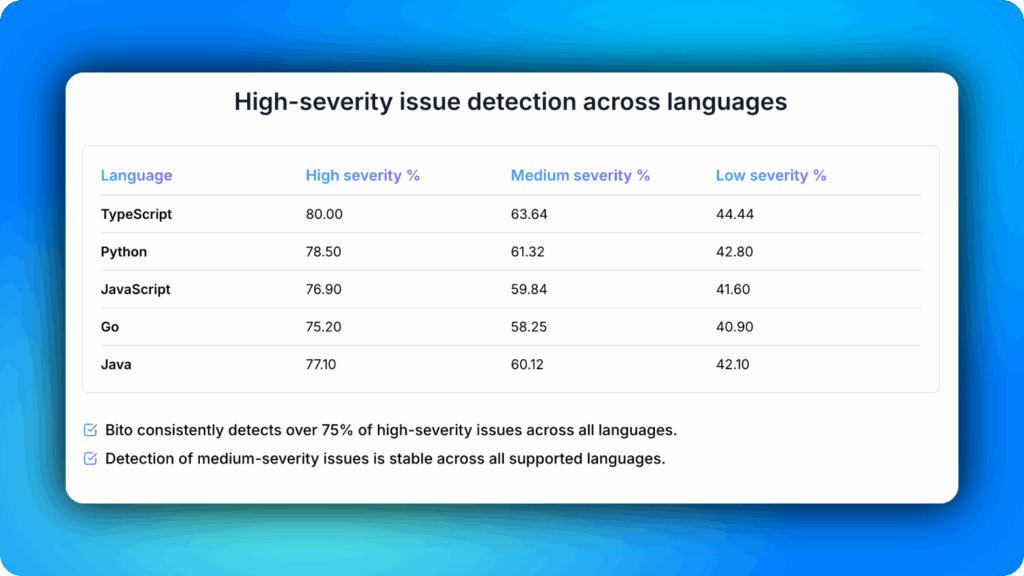
Severity-based detection
We also assessed how well Bito detected issues based on their severity levels. Across all tested languages, Bito consistently identified over 75 percent of high-severity issues.
Detection rates for medium-severity issues were stable at just over 60 percent. The tool was calibrated to minimize low-severity detections to reduce noise and focus on more critical problems.
Cost efficiency
Manual code reviews are resource-intensive, typically costing between $1,200 and $1,500 per 1,000 lines of code.
Bito’s automated code review reduced this cost to approximately $150 to $300 per 1,000 lines, representing a 75 to 85 percent reduction.
This efficiency gain translates to faster development cycles and smoother CI/CD code review automation, reducing time spent on iterative review processes.
What this means for your engineering team
If you’re running reviews across multiple repos and stacks, you want something that stays accurate no matter what language your team is writing in. That’s what the benchmark shows. Bito stays consistent.
It flags the real issues that actually affect code quality and review velocity. That means fewer back-and-forth. Less context switching. And more time for your team to focus on the kind of review feedback that actually helps.
If you want to see how Bito fits in your workflow, book a demo to talk to our team or run it on your own code like I did.
FAQs About the AI Code Review Benchmark
Q1. How did you benchmark different AI code review tools in this report?
We created a truth set of known issues across real repositories, then ran each AI code review tool against the same pull requests. We measured how many real issues each tool caught and how many of its suggestions were actually correct and useful.
Q2. What are the most important metrics when comparing AI code review tools?
Coverage and precision matter most. Coverage shows how many real issues the tool finds, while precision tells you how many of its comments are accurate and worth acting on. A good AI code review tool needs strong numbers on both.
Q3. Why is high coverage not enough on its own?
If a tool flags everything, you get flooded with noise and developers start ignoring it. You want a balance where the AI surfaces a meaningful share of real problems without drowning the team in false positives.
Q4. Can I reproduce this benchmark on my own codebase?
Yes. You can start by tagging known issues in a few representative services, running different AI code review tools on those PRs, and comparing how many issues each one catches and how useful the comments are to your senior reviewers.
Q5. How often should benchmarks for AI code review tools be updated?
Since vendors ship frequent model and product changes, a benchmark should be refreshed regularly. Treat any benchmark as a snapshot, and re-run tests when you see big product updates or if you are about to sign a longer-term contract.





