
The release of Claude 2.1 by Anthropic marks a significant advancement in the capabilities of large language models (LLMs). This new version boasts an industry-leading 200K token context window among other features, setting new standards in AI performance. This article delves into the Claude 2.1 benchmarks, based on a comprehensive test conducted to evaluate its capabilities.
Overview of Claude 2.1?
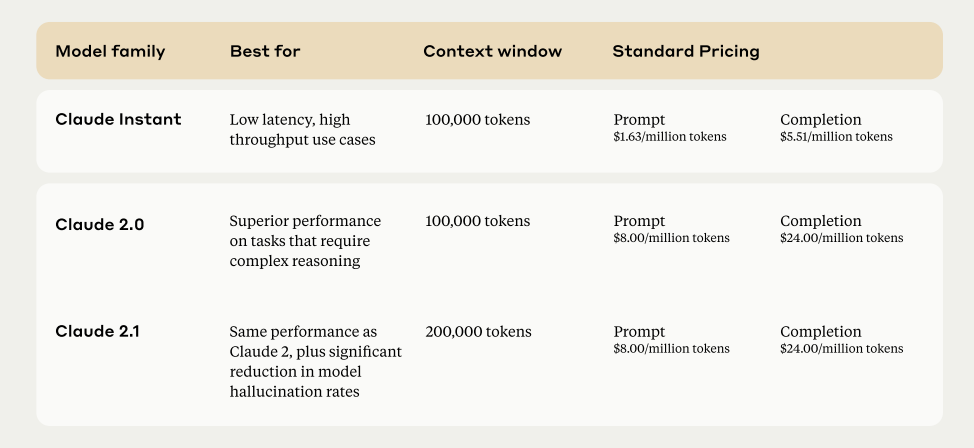
Claude 2.1 is the newest iteration of the Claude model series, known for its advanced AI functionalities. This version is now available via API in Anthropic’s Console and is also the driving force behind the claude.ai chat experience. The standout feature of Claude 2.1 is its whopping 200K token context window, which is a significant upgrade and a first in the industry.
Key Features of Claude 2.1
- 200K Token Context Window: This massive context window can handle about 150,000 words or over 500 pages of material. It’s perfect for handling extensive documents like technical manuals, financial statements, or even lengthy literary works.
- Reduced Hallucination Rates: Claude 2.1 exhibits a remarkable reduction in false statements, making it more reliable and trustworthy for businesses and other applications.
- Advanced Comprehension and Summarization: Particularly for long and complex documents, Claude 2.1 shows enhanced comprehension and summarization abilities, crucial for handling legal documents and technical specifications.
- API Tool Use: A beta feature that allows Claude to integrate with various processes, products, and APIs, enhancing its utility in various operations.
Developer Experience Enhancements
The developer experience with Claude 2.1 is more streamlined, with improvements like the Workbench product for easier prompt testing and the introduction of system prompts for customizable performance.
The “Needle in a Haystack” Analysis

To test the limits of Claude 2.1’s extended context window, a comprehensive analysis was conducted, aptly named the “needle in a haystack” test. The goal was to understand how well Claude 2.1 can recall information from different depths of a document.
Test Methodology
The test involved using Paul Graham’s essays as background tokens to reach up to 200K tokens. A random statement was placed at various depths in the document, and Claude 2.1 was tasked with identifying this statement. The process was repeated for different document depths and context lengths.
Findings of the Test
- Recall Ability: Claude 2.1 could recall facts from various depths of the document, with near-perfect accuracy at the very top and bottom.
- Performance Variance: The recall performance was less effective at the top compared to the bottom of the document, a trait similar to GPT-4.
- Decline in Recall Performance: As the token count approached 90K, the recall ability at the bottom started to deteriorate.
- Context Length and Accuracy: It was observed that less context generally meant more accuracy in recall.
Implications
- Prompt Engineering: Fine-tuning your prompt and conducting A/B tests can significantly affect retrieval accuracy.
- No Guarantee of Fact Retrieval: It’s crucial not to assume that facts will always be retrieved accurately.
- Position of Information: The placement of facts within the document impacts their recall, with the beginning and latter half showing better recall rates.
Why This Test Matters
This test is vital for understanding the practical limits and capabilities of LLMs like Claude 2.1. It’s not just about pushing the boundaries of AI technology but also about building a practical understanding of these models for real-world applications.
Example Code for Evaluation
Pressure Testing Claude 2.1-200K: A simple ‘needle in a haystack’ analysis to test in-context retrieval ability of Claude 2.1-200K context. Basically, this code helps us in simple retrieval from LLM models at various context lengths to measure accuracy.
Next Steps and Notes
For further rigor, a key:value retrieval step could be introduced in future tests. It’s also essential to note that varying the prompt, question, and background context can impact the model’s performance. The involvement of the Anthropic team was purely logistical, ensuring the test’s integrity and independence.
Conclusion
The release of Claude 2.1 marks a significant milestone in the evolution of large language models. With its expanded context window, improved accuracy, and new features, it opens up a plethora of possibilities for users and developers alike. However, as the test findings suggest, understanding the nuances of how these models work and their limitations is crucial for maximizing their potential in practical applications.
As Claude 2.1 continues to evolve and improve, it’s an exciting time for AI practitioners and enthusiasts. The advancements in this model are a testament to the incredible progress in the field of artificial intelligence and its growing impact on various sectors.
Stay tuned for more updates and explorations into the world of AI as we continue to witness and participate in this extraordinary journey of technological advancement.





