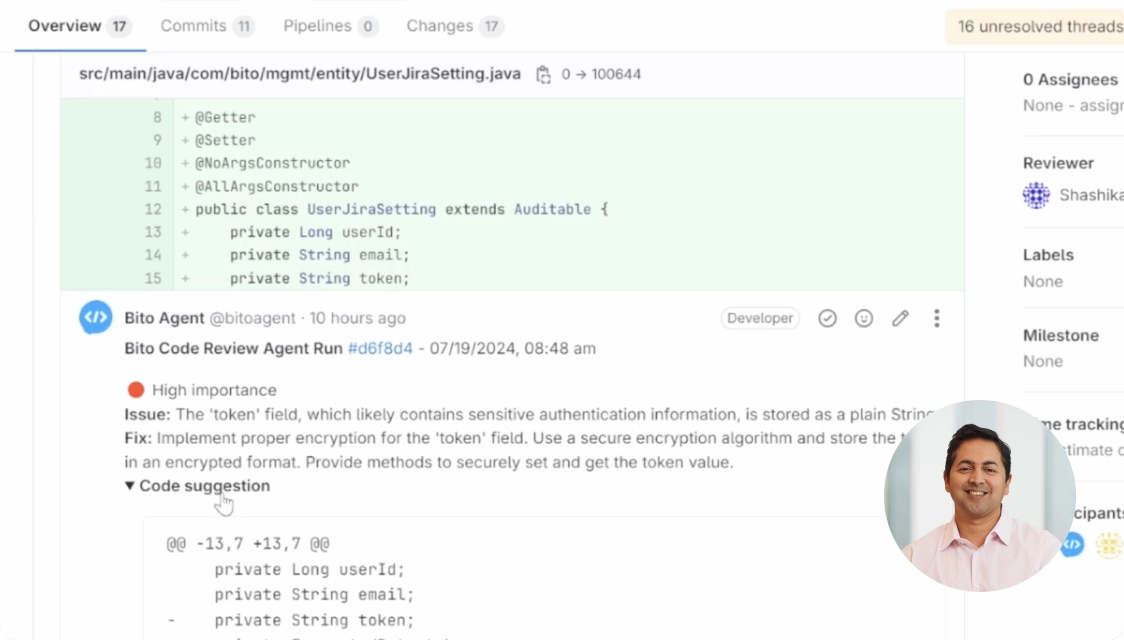
AI that understands your code
Bito deeply understands your codebase to do a human-like code review.
See how we do it ![]()
Bito deeply understands your codebase to do a human-like code review.
See how we do it ![]()
Install on IDEs like IntelliJ, WebStorm etc.
